
Содержание
Предисловие: мир взаимосвязанных данных: В наше время информация — это не просто набор чисел и строк, а сложная система, которая описывает все аспекты нашей жизни. Представьте себе библиотеку, где книги разбросаны по полкам хаотично, без какой-либо системы каталогизации. Найти нужную книгу в такой библиотеке будет практически невозможно. Аналогично обстоит дело с данными в компьютерных системах. Без правильной организации хранения информации работа с ней становится крайне затруднительной.
Базы данных — это инструменты, которые помогают нам структурировать информацию. Они позволяют хранить данные в удобном для анализа и использования виде. Одним из ключевых аспектов работы с базами данных является создание связей между таблицами. Эти связи позволяют нам эффективно организовывать, извлекать и анализировать информацию, делая работу с данными не только удобной, но и увлекательной.
В этой статье мы погрузимся в мир реляционных баз данных, разберем принципы их построения, методы нормализации, типы соединений и многое другое. Мы расскажем обо всем максимально подробно, чтобы даже те, кто никогда не сталкивался с базами данных, смогли понять основы этого удивительного мира.
Основы реляционных баз данных: что скрывается за термином?

Реляционные базы данных (от англ. "relation" — отношение) представляют собой систему хранения данных, где информация организована в виде таблиц. Каждая таблица состоит из строк (записей) и столбцов (полей). Таблицы связаны между собой через уникальные идентификаторы, что позволяет избежать дублирования данных и обеспечивает целостность информации.
Чтобы лучше понять, как это работает, представьте себе магазин. В этом магазине есть покупатели, товары и заказы. Если бы мы хранили всю эту информацию в одной таблице, то каждый раз, когда покупатель совершает заказ, нам пришлось бы дублировать его имя, адрес и другие данные. Это привело бы к огромным объемам лишней информации, которую трудно поддерживать и анализировать.
Вместо этого мы можем создать несколько таблиц:
| Таблица "Пользователи" | ID | Имя | |
|---|---|---|---|
| 1 | Анна | ||
| 2 | Иван |
| Таблица "Заказы" | OrderID | UserID | Товар |
|---|---|---|---|
| 101 | 1 | Книга | |
| 102 | 2 | Ноутбук |
В данном примере таблица "Заказы" связана с таблицей "Пользователи" через поле UserID. Это позволяет нам узнать, какой пользователь сделал заказ, без необходимости хранить всю информацию о нем в каждой записи. Такой подход не только экономит место, но и упрощает поддержку данных.
Реляционные базы данных используют язык SQL (Structured Query Language) для управления данными. Этот язык позволяет выполнять запросы, добавлять, изменять и удалять данные, а также создавать и модифицировать структуры таблиц. SQL — это универсальный инструмент, который используется практически во всех современных базах данных, таких как MySQL, PostgreSQL, Oracle и Microsoft SQL Server.
Нормализация данных: искусство порядка
Нормализация — это процесс организации данных в базе данных для минимизации избыточности и улучшения целостности. Она включает несколько этапов, называемых нормальными формами. Давайте разберем их подробнее.
Первая нормальная форма (1NF): На этом этапе устраняются повторяющиеся группы данных. Например, если у нас есть поле "Телефоны", содержащее несколько номеров, его нужно разделить на отдельные строки или таблицы. Это необходимо, чтобы каждое значение в ячейке было атомарным (неделимым).
Пример до нормализации:
| До нормализации | ID | Имя | Адрес | Телефоны |
|---|---|---|---|---|
| 1 | Анна | Москва | +7123456,+7987654 |
Пример после нормализации:
| После нормализации | Таблица "Пользователи" | ID | Имя | Адрес |
|---|---|---|---|---|
| 1 | Анна | Москва |
| Таблица "Телефоны" | PhoneID | UserID | Телефон |
|---|---|---|---|
| 1 | 1 | +7123456 | |
| 2 | 1 | +7987654 |
Вторая нормальная форма (2NF): Здесь устраняется частичная зависимость. Все неключевые поля должны зависеть от всего первичного ключа. Например, если у нас есть таблица "Заказы" с полями "OrderID", "ProductID" и "ProductName", то поле "ProductName" должно быть перенесено в отдельную таблицу "Товары", так как оно зависит только от "ProductID".
Третья нормальная форма (3NF): На этом этапе устраняется транзитивная зависимость. Неключевые поля не должны зависеть от других неключевых полей. Например, если у нас есть таблица "Сотрудники" с полями "EmployeeID", "DepartmentID" и "DepartmentName", то поле "DepartmentName" должно быть перенесено в отдельную таблицу "Отделы", так как оно зависит от "DepartmentID", а не от "EmployeeID".
Нормализация — это не просто технический процесс, а философия, которая помогает нам создавать базы данных, которые легки в поддержке, эффективны и надежны.
Как создаются связи: стратегии и методы
Связи между таблицами организуются через ключи. Основные типы ключей:
- Первичный ключ (Primary Key): Уникальный идентификатор записи в таблице. Он должен быть уникальным и не допускать пустых значений (NULL).
- Внешний ключ (Foreign Key): Поле, которое ссылается на первичный ключ другой таблицы. Оно используется для установления связи между таблицами.
Пример создания связи в SQL:
CREATE TABLE Users ( UserID INT PRIMARY KEY, Name VARCHAR(50), Email VARCHAR(50) ); CREATE TABLE Orders ( OrderID INT PRIMARY KEY, UserID INT, Product VARCHAR(50), FOREIGN KEY (UserID) REFERENCES Users(UserID) );
В этом примере таблица "Orders" связана с таблицей "Users" через внешний ключ UserID. Это позволяет нам легко находить все заказы конкретного пользователя.
Создание связей — это не только техническая задача, но и стратегическое решение. Правильно организованные связи позволяют нам избежать дублирования данных, упростить обновление информации и обеспечить целостность данных.
Отношения между таблицами: один к одному, один ко многим, многие ко многим
Существует три основных типа отношений между таблицами:
- Один к одному (One-to-One): Одна запись в первой таблице связана только с одной записью во второй таблице. Пример: паспорт и человек. У каждого человека может быть только один паспорт, и каждый паспорт принадлежит только одному человеку.
- Один ко многим (One-to-Many): Одна запись в первой таблице может быть связана с несколькими записями во второй таблице. Пример: пользователь и его заказы. Один пользователь может сделать множество заказов, но каждый заказ принадлежит только одному пользователю.
- Многие ко многим (Many-to-Many): Записи в обеих таблицах могут быть связаны с несколькими записями в другой таблице. Пример: студенты и курсы. Один студент может записаться на несколько курсов, и на одном курсе может учиться несколько студентов. Для реализации таких отношений используется промежуточная таблица.
Пример реализации отношения "многие ко многим":
CREATE TABLE Students ( StudentID INT PRIMARY KEY, Name VARCHAR(50) ); CREATE TABLE Courses ( CourseID INT PRIMARY KEY, Title VARCHAR(50) ); CREATE TABLE Enrollments ( EnrollmentID INT PRIMARY KEY, StudentID INT, CourseID INT, FOREIGN KEY (StudentID) REFERENCES Students(StudentID), FOREIGN KEY (CourseID) REFERENCES Courses(CourseID) );
В этом примере таблица "Enrollments" выступает в роли промежуточной таблицы, которая связывает студентов и курсы.
Типы соединений в SQL: искусство объединения данных
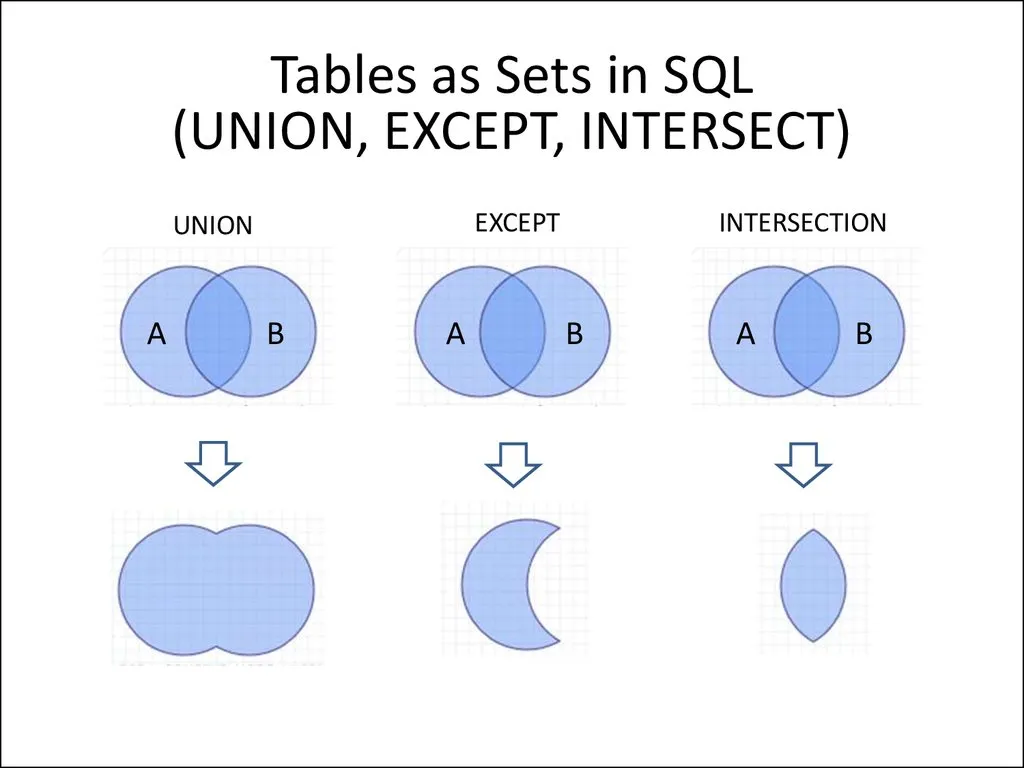
Для извлечения данных из нескольких таблиц используются различные типы соединений (JOIN):
- INNER JOIN: Возвращает только те записи, которые имеют совпадения в обеих таблицах. Это наиболее часто используемый тип соединения.
- LEFT JOIN: Возвращает все записи из левой таблицы и соответствующие записи из правой таблицы. Если в правой таблице нет совпадений, то возвращаются NULL-значения.
- RIGHT JOIN: Возвращает все записи из правой таблицы и соответствующие записи из левой таблицы. Если в левой таблице нет совпадений, то возвращаются NULL-значения.
- FULL OUTER JOIN: Возвращает все записи из обеих таблиц. Если в одной из таблиц нет совпадений, то возвращаются NULL-значения.
Пример использования INNER JOIN:
SELECT Users.Name, Orders.Product FROM Users INNER JOIN Orders ON Users.UserID = Orders.UserID;
Этот запрос вернет список всех пользователей и их заказов. Если у пользователя нет заказов, он не будет включен в результат.
Пример использования LEFT JOIN:
SELECT Users.Name, Orders.Product FROM Users LEFT JOIN Orders ON Users.UserID = Orders.UserID;
Этот запрос вернет список всех пользователей, даже если у них нет заказов. В этом случае в поле "Product" будет значение NULL.
Облачные базы данных: шаг в будущее
Облачные базы данных предлагают множество преимуществ перед традиционными решениями:
- Масштабируемость: Возможность легко увеличивать или уменьшать ресурсы в зависимости от нагрузки. Например, если ваш сайт внезапно стал популярным, облачная база данных может автоматически расширить свои ресурсы, чтобы справиться с увеличившимся потоком данных.
- Доступность: Данные доступны из любой точки мира с подключением к интернету. Это особенно важно для компаний, которые работают в разных странах и часовых поясах.
- Безопасность: Облачные провайдеры обеспечивают высокий уровень защиты данных, включая шифрование, резервное копирование и защиту от кибератак.
- Автоматизация: Резервное копирование, обновления и мониторинг выполняются автоматически. Это освобождает вас от рутинных задач и позволяет сосредоточиться на более важных аспектах работы.
Примером облачных баз данных являются такие сервисы, как Amazon RDS, Google Cloud SQL и Microsoft Azure SQL Database. Они предоставляют широкие возможности для работы с данными, начиная от простого хранения и заканчивая сложным анализом больших объемов информации.
Заключение: гармония данных
Создание и управление связями между таблицами баз данных — это искусство, требующее глубокого понимания принципов реляционных систем. От нормализации до выбора типа соединения каждый шаг важен для обеспечения эффективности и надежности системы. Использование облачных технологий открывает новые горизонты для работы с данными, делая их доступными и безопасными.
Правильная организация данных — это не только техническая задача, но и философский подход к порядку и гармонии в мире информации. Когда данные структурированы правильно, они становятся мощным инструментом для принятия решений, анализа и развития бизнеса. Надеемся, что эта статья помогла вам лучше понять, как устроены базы данных и как работают связи между таблицами. Желаем вам успехов в освоении этого удивительного мира!
Когда речь заходит о хранении и управлении базами данных, особенно с использованием MySQL, важно учитывать не только внутреннюю организацию данных, но и среду, в которой они размещаются. Хостинг для MySQL играет ключевую роль в обеспечении производительности, безопасности и доступности ваших данных. Современные хостинг-провайдеры предлагают специализированные решения для MySQL, которые включают предварительно настроенные серверы, автоматическое резервное копирование и мониторинг производительности. Например, если вы создаете приложение с множеством связанных таблиц, таких как пользователи, заказы и товары, надежный хостинг позволит вам сосредоточиться на логике работы с данными, а не на технических аспектах их хранения. Кроме того, облачные хостинги для MySQL, такие как Amazon RDS, Google Cloud SQL или DigitalOcean Managed Databases, предоставляют возможность масштабирования ресурсов в реальном времени, что особенно полезно, когда количество записей в таблицах начинает стремительно расти. Таким образом, выбор правильного хостинга становится неотъемлемой частью успешной работы с базами данных, дополняя все усилия по организации связей и оптимизации структуры данных.