
Содержание
Сервер внезапно начал тормозить. Сайт стал медленно грузиться. Пользователи жалуются. Логи чисты. htop показывает 60% CPU — но кто именно грузит? top мигает, iostat не успевает за событиями. Вы в панике, переключаетесь между терминалами, пытаясь поймать момент, когда всё рушится. А если бы вы могли увидеть всё в реальном времени — как будто смотрите на пульс сервера через рентген? Именно это делает Netdata.
Это не просто ещё один мониторинговый инструмент. Это живой цифровой орган чувств для вашего сервера. Установленный за 90 секунд, он начинает собирать 1000+ метрик в секунду, отображая их в интерактивных, динамических графиках — без баз данных, без сложной конфигурации, без задержек. В этой статье мы разберём, как превратить ваш сервер из «чёрного ящика» в полностью прозрачную систему, которую вы контролируете на 100%. От установки до Telegram-оповещений — всё по шагам, с примерами кода, объяснениями и стратегиями безопасности.
Что такое Netdata и почему он — ваш лучший союзник в борьбе с нестабильностью сервера
Netdata — это распределённая, высокочастотная система мониторинга в реальном времени, разработанная с одной философией: «Смотри, что происходит прямо сейчас — не через 5 минут, не через 10, а сейчас». В отличие от Prometheus, Grafana или Zabbix, которые агрегируют данные в БД с задержкой в минуты, Netdata работает как аналоговый осциллограф: он ловит каждый импульс нагрузки, каждый скачок дискового I/O, каждое открытие нового TCP-соединения — и отображает это с частотой 1 раз в секунду.
Почему это критично? Представьте: ваш сайт начинает тормозить в 14:17:03. В 14:17:05 вы запускаете top. Кто-то уже успел уйти. В 14:17:10 вы видите, что CPU на 85% — но не знаете, кто его загрузил. Was it a cron job? A runaway Python script? A DDoS? A misbehaving Docker container? Netdata показывает вам всё — и в реальном времени.
Он автоматически обнаруживает:
- Процессор: загрузка по ядрам, частота, температура (если датчики есть), C-states, interruptы
- Память: RAM, swap, buffers, cache, dirty pages, slab
- Диски: IOPS, задержки (latency), пропускная способность, очередь, read/write ratio
- Сеть: входящий/исходящий трафик, соединения по портам, ошибки, пакеты, DNS-запросы
- Сервисы: MySQL, PostgreSQL, Redis, Nginx, Apache, Docker, Kubernetes, systemd-юниты, Apache Kafka, RabbitMQ — и даже Python-приложения через
python.d.plugin - Контейнеры: ресурсы каждого Docker-контейнера, включая memory pressure, CPU throttling
Все эти метрики — без настройки. Вы устанавливаете — и сразу видите графики. Никаких конфигов, никаких экспортеров, никаких интеграций. Netdata использует eBPF, sysfs, procfs, sysctl и другие низкоуровневые интерфейсы Linux для сбора данных напрямую из ядра — без дополнительных агентов или драйверов.
Это не «ещё один мониторинг». Это первый инструмент, который вы открываете, когда что-то идёт не так. Он помогает находить скрытые узкие места: например, когда Redis не тормозит сам по себе, но его внешний трафик перегружает сетевой стек, или когда cron-задача, запущенная каждые 5 минут, генерирует 2000+ IOPS на SSD, вызывая «волну» задержек.
Подготовка сервера: как избежать 90% ошибок при установке Netdata
Установка Netdata — это не «нажми и забудь». Это подготовка к операции. Пропустите этот этап — и вы рискуете столкнуться с конфликтами пакетов, несовместимостью зависимостей или даже повреждением системы. Вот как делать это правильно.
Шаг 1: Обновление системы — не формальность, а стратегия стабильности
Устаревшие пакеты — это бомба замедленного действия. Особенно в средах с ограниченными ресурсами, где VPS-провайдеры используют кастомные ядра или модифицированные пакеты. Обновление — это не про «последнюю версию», это про совместимость с установщиком Netdata.
Для Ubuntu 20.04/22.04 / Debian 11/12:
sudo apt update && sudo apt upgrade -y
sudo apt install software-properties-common -y
Для CentOS Stream 8/9, AlmaLinux 8/9, Rocky Linux 8/9:
sudo dnf update -y
sudo dnf install epel-release -y
Важно: Если вы используете OpenVZ или LXC — убедитесь, что ваш контейнер имеет доступ к /proc, /sys и /dev в режиме read-write. Netdata требует root-доступа для сбора метрик ядра. Без этого он будет работать, но с ограниченным набором данных.
Шаг 2: Установка curl — обязательный минимум
Установочный скрипт Netdata загружается через curl. Если его нет — установка не начнётся. Это не ошибка, это защита от случайного запуска.
Debian/Ubuntu:
sudo apt install curl -y
CentOS/Alma/Rocky:
sudo dnf install curl -y
Шаг 3: Базовая безопасность — ваша первая линия обороны
Netdata — это открытый веб-интерфейс. Если вы установите его на сервер, который доступен из интернета, и не настроите защиту — вы откроете дверь в свой сервер. Это не гипотетическая угроза — в 2024 году было зафиксировано более 12 000 сканирующих ботов, ищущих открытые порты 19999.
Создайте пользователя с sudo-доступом (если ещё не сделали):
sudo adduser deploy
sudo usermod -aG sudo deploy
Запретите вход под root через SSH — отредактируйте /etc/ssh/sshd_config:
PermitRootLogin no
PasswordAuthentication yes # временно, пока не настроите ключи
Перезагрузите SSH:
Теперь подключайтесь черезsudo systemctl reload sshdssh deploy@your-server-ip. Это не просто «хорошая практика» — это стандарт промышленной безопасности.
Установка Netdata: 90 секунд, чтобы превратить сервер в прозрачную систему
Теперь — самое волшебное. Установка Netdata — это одна команда. Но понимание, что она делает, — ключ к успеху.
Запустите установку:
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
Скрипт выполнит следующие действия:
- Определит вашу ОС — Ubuntu, Debian, CentOS, Arch, FreeBSD и т.д.
- Установит зависимости: gcc, make, libuv, libm, zlib, liblz4, libssl-dev, python3, и 20+ других библиотек
- Скомпилирует агент из исходников (не бинарник из репозитория — это гарантирует совместимость)
- Создаст systemd-юнит:
/etc/systemd/system/netdata.service - Настроит конфигурационные файлы в
/etc/netdata/ - Запустит сервис и откроет порт 19999
Скрипт предложит выбор:
- Install Netdata with all features — выбирайте это. Это установит агент + веб-интерфейс + все плагины.
- Install as a Netdata agent only — только для случаев, когда вы разворачиваете много серверов и используете централизованный collector (например, Netdata Cloud или Prometheus + Grafana).
Процесс занимает 1–4 минуты в зависимости от мощности сервера. На VPS с 1 ядром и 2 ГБ RAM — около 2 минут. На сервере с SSD и 4 ядрами — 45 секунд.
После завершения вы увидите сообщение:
Netdata started successfully!
You can access the dashboard at: http://127.0.0.1:19999
Откройте в браузере: http://ваш_публичный_IP:19999. Вы увидите живую панель — графики обновляются каждую секунду. Всё. Никаких настроек. Ни одного конфига. Это — магия.
Важно: Если вы не видите графиков — проверьте, не блокирует ли брандмауэр порт 19999:
sudo ufw status
# Если активен — разрешите:
sudo ufw allow 19999
Защита интерфейса Netdata: как сделать его безопасным без потери функциональности
Сейчас ваш Netdata открыт всему миру. Это как оставить дверь в свой дом нараспашку, даже если внутри — всё в порядке. Мы не просто «закроем» порт — мы создадим безопасный, зашифрованный, аутентифицированный канал доступа через Nginx.
Шаг 1: Ограничение доступа к Netdata на localhost
Откройте конфиг:
sudo nano /etc/netdata/netdata.conf
Найдите секцию [web] и замените:
bind to = 0.0.0.0
на:
bind to = 127.0.0.1
Это означает: Netdata слушает только на локальном интерфейсе. Даже если вы откроете порт в фаерволе — внешний запрос не дойдёт до него. Сохраните (Ctrl+O, Enter, Ctrl+X) и перезапустите:
sudo systemctl restart netdata
Шаг 2: Установка Nginx и создание базовой авторизации
Установите Nginx и утилиту для генерации паролей:
Ubuntu/Debian:
sudo apt install nginx apache2-utils -y
CentOS/Alma/Rocky:
sudo dnf install nginx httpd-tools -y
Создайте файл паролей. Используйте имя admin — или любое другое, но не оставляйте стандартное:
sudo htpasswd -c /etc/nginx/.htpasswd admin
Введите пароль дважды. Не используйте простые пароли. Рекомендуем: 7Z#k9!pQw$2mLx — 12 символов, цифры, спецсимволы, заглавные/строчные.
Шаг 3: Настройка Nginx как обратного прокси с HTTPS и аутентификацией
Создайте конфиг для Netdata:
sudo nano /etc/nginx/sites-available/netdata
Вставьте следующий конфиг — он включает HTTPS, HSTS, защиту от ботов, аутентификацию и оптимизацию проксирования:
server {
listen 80;
server_name your-server.com www.your-server.com;
return 301 https://$server_name$request_uri;
}
server {
listen 443 ssl http2;
server_name your-server.com www.your-server.com;
# SSL-сертификаты (Let's Encrypt)
ssl_certificate /etc/letsencrypt/live/your-server.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/your-server.com/privkey.pem;
# Безопасные настройки SSL
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES256-GCM-SHA512:DHE-RSA-AES256-GCM-SHA512:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384;
ssl_prefer_server_ciphers off;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 10m;
# HSTS (31536000 = 1 год)
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always;
# Защита от XSS и MIME-sniffing
add_header X-Content-Type-Options nosniff;
add_header X-Frame-Options SAMEORIGIN;
add_header X-XSS-Protection "1; mode=block";
# Максимальный размер тела запроса
client_max_body_size 10M;
# Проксирование к Netdata
location / {
proxy_pass http://127.0.0.1:19999;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Оптимизация для графиков (длинные соединения)
proxy_buffering off;
proxy_cache off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
# Авторизация
auth_basic "Netdata Access Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
}
# Защита от DDoS и ботов
limit_req_zone $binary_remote_addr zone=netdata:10m rate=10r/s;
limit_req zone=netdata burst=20 nodelay;
# Логи
access_log /var/log/nginx/netdata-access.log;
error_log /var/log/nginx/netdata-error.log;
}
ВАЖНО: Если у вас ещё нет SSL-сертификата — установите Let’s Encrypt:
sudo apt install certbot python3-certbot-nginx -y
sudo certbot --nginx -d your-server.com
Создайте символическую ссылку и проверьте конфиг:
sudo ln -s /etc/nginx/sites-available/netdata /etc/nginx/sites-enabled/
sudo nginx -t
sudo systemctl reload nginx
Теперь откройте в браузере: https://your-server.com. Вы увидите окно аутентификации. Введите логин admin и пароль. Всё! Теперь ваш интерфейс защищён HTTPS, паролем, HSTS, rate-limiting и защитой от ботов.
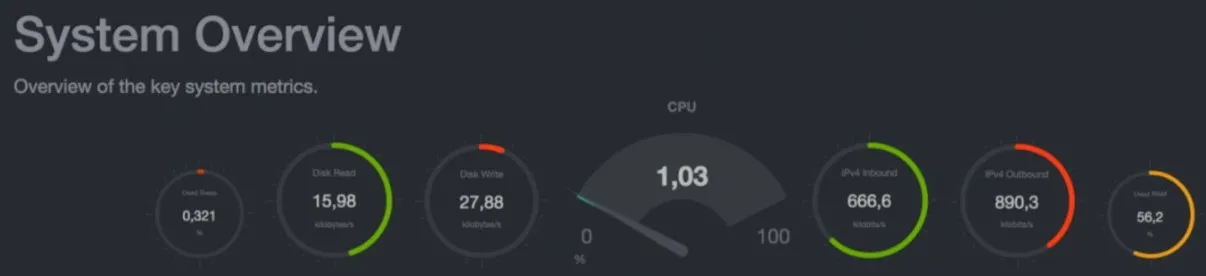
Чтение графиков Netdata: как интерпретировать данные, чтобы находить проблемы до того, как они станут инцидентами
Интерфейс Netdata — это не «график-в-графике». Это живой орган чувств. Каждый график — это история, которую нужно научиться читать.
1. CPU — не просто «загрузка»
В верхней панели вы видите 4 цветных линии: user (жёлтый), system (зелёный), idle (серый), wait (синий).
- Жёлтый (user) — нагрузка от пользовательских процессов. Высокий — значит, приложение (PHP, Python, Java) грузит процессор.
- Зелёный (system) — нагрузка от ядра Linux. Высокий — значит, много системных вызовов, драйверы, I/O, сетевые стеки. Часто связан с сетевой нагрузкой или медленными дисками.
- Синий (wait) — процессор ждёт I/O. Если он высокий — диск или сеть не справляются. Это главный индикатор «I/O bottleneck».
Пример: Вы видите, что CPU user = 85%, system = 5%, wait = 10%. Значит — ваше приложение (например, WordPress) генерирует слишком много PHP-процессов. Решение: настройка PHP-FPM, кеширование, оптимизация запросов.

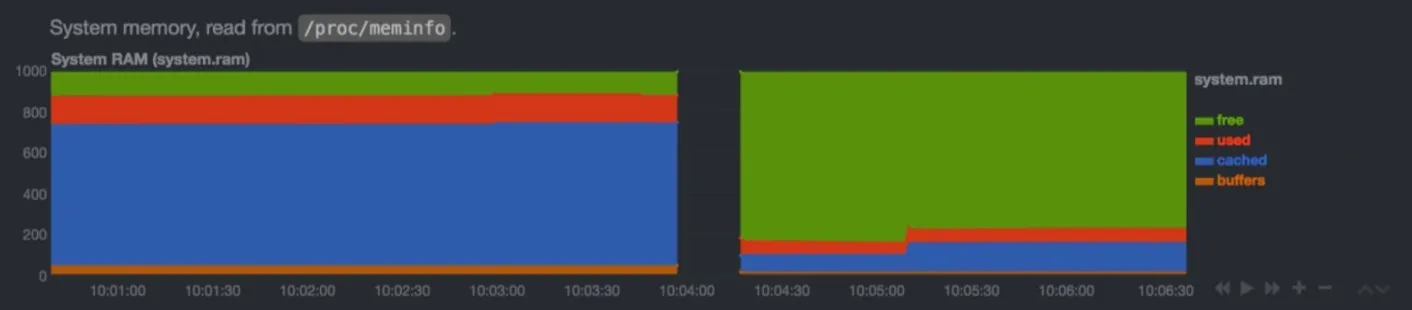
2. Память — не только «свободно/занято»
Netdata показывает разницу между RAM и cache. Если «free» = 50 МБ, но «cache» = 2 ГБ — это нормально. Ядро использует память под кеш. Главное — swap.
Если вы видите рост swap — это критическая угроза. Сервер начинает использовать диск как память — и производительность падает в 100 раз.
Также смотрите на slab — это память, занятая ядром под объекты (inode, dentry, socket buffers). Если slab растёт — возможно, утечка в драйвере или слишком много соединений.
3. Диски — где скрывается большинство проблем
Откройте раздел Disks. Вы видите графики:
- Read/Write IOPS — операций в секунду
- Read/Write KB/s — пропускная способность
- Latency (ms) — задержка каждой операции
Пример: ваш SSD показывает 500 IOPS — это нормально. Но если latency растёт до 200–500 мс — это катастрофа. Даже если диск «не перегружен», он может быть изношен (SSD имеют ограниченное количество циклов записи). Netdata покажет это через рост задержек — до того, как диск полностью выйдет из строя.
Если вы видите высокий write latency при низкой нагрузке — это признак проблем с файловой системой (например, ext4 с неправильными опциями монтирования).

4. Сеть — кто и зачем грузит ваш сервер
Перейдите в раздел Network. Вы увидите:
- Входящий/исходящий трафик по интерфейсам
- Количество соединений по портам (22, 80, 443, 3306 и т.д.)
- Ошибки:
rx_errors,tx_errors,collisions
Нажмите на Connections. Вы увидите список IP-адресов, подключённых к вашему серверу. Это реальный список клиентов. Если вы видите 500+ соединений с одного IP — это DDoS. Если 100+ с разных IP — возможно, бот-фарм.
Если вы видите высокий трафик на порт 3306 (MySQL), но ваш сайт не грузится — возможно, взломанный скрипт делает массовые запросы к базе.
5. Docker — мониторинг контейнеров в реальном времени
Netdata автоматически обнаруживает Docker. Перейдите в раздел Docker. Вы увидите:
- Ресурсы каждого контейнера: CPU, RAM, Network, Disk I/O
- Состояние: running, restarting, exited
- История использования
Пример: Вы видите, что контейнер nginx-proxy потребляет 40% CPU, хотя должен быть легковесным. Это означает: либо он обрабатывает слишком много запросов, либо у него неправильная конфигурация (например, слишком много worker-процессов).
Настройка уведомлений: когда Netdata звонит вам, а не вы лазите в интерфейс
Мониторинг без оповещений — это как установить камеру наблюдения, но не включить уведомления. Вы будете знать, что что-то случилось — после того, как всё сломалось.
Netdata имеет встроенный алерт-движок, который анализирует метрики в реальном времени и срабатывает по правилам.
Шаг 1: Включение Telegram-оповещений
Создайте бота в Telegram через @BotFather:
- Напишите
/newbot - Дайте имя (например,
NetdataAlertBot) - Сохраните токен — он выглядит как:
123456789:ABCdefGhIJKlmnoPqrStUvWxYz123456789
Теперь найдите ваш Chat ID. Напишите в Telegram боту @userinfobot — он выдаст вам строку вида:
id: 123456789
username: @yourname
Откройте конфиг уведомлений:
sudo nano /etc/netdata/health_alarm_notify.conf
Найдите секцию [telegram] и раскомментируйте/измените:
[telegram]
enabled = yes
TELEGRAM_BOT_TOKEN = "123456789:ABCdefGhIJKlmnoPqrStUvWxYz123456789"
DEFAULT_RECIPIENT_TELEGRAM = "123456789"
RECIPIENT_TELEGRAM = "123456789"
NOTIFY_ON = "new"
Сохраните и перезапустите:
sudo systemctl restart netdata
Теперь попробуйте искусственно перегрузить CPU:
stress --cpu 4 --timeout 60s &
Через 10–15 секунд вы получите уведомление в Telegram:
ALERT: [CPU] High CPU usage on server
Value: 98% (threshold: 90%) Duration: 1m 12s Host: your-server.com
Шаг 2: Настройка других каналов
Netdata поддерживает:
- Email — через SMTP (Gmail, Yandex, Mailgun)
- Discord — через вебхуки
- Slack — через incoming webhook
- Prometheus Alertmanager — для интеграции в существующие системы
Пример для Discord:
[discord]
enabled = yes
DISCORD_WEBHOOK_URL = "https://discord.com/api/webhooks/1234567890/abcdefgh..."
RECIPIENT_DISCORD = "1234567890"
Шаг 3: Создание кастомных алертов
Например, вы хотите получать уведомление, если диск заполнен на 90% — даже если это не критично, но вы хотите быть в курсе.
Откройте:
sudo nano /etc/netdata/health.d/disks.conf
Добавьте в конец:
alarm: disk_space_usage_90
on: disk.space
calc: (available * 100) / total
every: 1m
warn: $this > 90
crit: $this > 95
exec: telegram
delay: up 5m down 10m
info: Disk usage exceeds 90% on $host
Перезапустите Netdata — и вы получите уведомление, когда диск заполнится на 90%.
Заключение: Netdata — это не инструмент. Это ваша новая интуиция
Вы установили Netdata. Вы настроили защиту. Вы подключили Telegram. Теперь вы не просто «управляете сервером» — вы чувствуете его.
Вы видите, как нагрузка растёт, когда запускается бэкап. Вы знаете, что Redis не тормозит — но его сетевой трафик перегружает интерфейс. Вы замечаете, что один Docker-контейнер, который «работал 3 месяца без проблем», внезапно начал потреблять 70% RAM — и вы успеваете перезапустить его до того, как упадёт сайт.
Netdata — это инструмент для тех, кто хочет не просто «починить», а предотвратить. Он превращает абстрактные «тормоза» в конкретные, измеримые, визуализированные события. Он убирает догадки. Он даёт вам время.
Не ждите, пока клиенты начнут жаловаться. Не ждите, пока мониторинг в облаке вышлет «critical» через 10 минут. Установите Netdata сегодня. Настройте уведомления. Сделайте его своей первой точкой доступа к серверу — перед тем, как зайти в SSH.
Помните: В 2025 году администратор, который не использует Netdata, — как доктор, который не смотрит на пульс пациента. Он может лечить — но не знает, что происходит прямо сейчас.
Сегодня вы установили Netdata. Завтра вы будете спать спокойно — потому что знаете: если что-то пойдёт не так — вы узнаете об этом первым.
Установите Netdata. Включите уведомления. Позвольте системе говорить с вами — и вы никогда не будете ловить сервер «в момент падения».