
Содержание
Представьте себе огромный город, где миллионы людей общаются одновременно. Каждый говорит на своем языке, использует разные устройства для связи, а информация передается с невероятной скоростью. Как организовать этот хаос так, чтобы никто не потерялся, а данные доходили до адресата быстро и точно? Именно эту задачу решает Apache Kafka — мощная система для потоковой обработки данных, которая стала незаменимым инструментом в мире больших данных.
Kafka — это распределенный брокер сообщений, работающий в режиме реального времени. Но что это значит? Давайте разберемся по порядку.
Зачем нужен брокер сообщений?
Представьте, что у вас есть два друга: один живет в Минске, а другой — в Нью-Йорке. Вы хотите отправить им одно и то же письмо, но у каждого свой способ получения информации: один предпочитает электронную почту, а другой — SMS. Если вы будете отправлять сообщения напрямую, вам придется учитывать все эти различия. А что, если друзей станет больше? Или если один из них временно недоступен?
Брокер сообщений — это как универсальный почтовый офис, который берет на себя всю сложность доставки. Его главная задача — обеспечить связь между приложениями или модулями в режиме реального времени. Он принимает сообщения от отправителей (продюсеров), хранит их и доставляет получателям (консьюмерам).
В случае с Apache Kafka брокер состоит из группы серверов, объединенных в кластер. Это позволяет системе быть отказоустойчивой: если один сервер выходит из строя, другие продолжают работу без сбоев.
История создания Apache Kafka
Kafka была разработана в LinkedIn в 2010 году. Ее создатель, Джей Крепс, назвал систему в честь своего любимого писателя Франца Кафки. Почему именно так? Возможно, потому что, как и произведения Кафки, система изначально была задумана как инструмент для работы с большими объемами текстовых данных. В 2011 году исходный код был опубликован, а в 2012 году проект попал в инкубатор Apache Software Foundation. Сегодня Kafka — это зрелое open-source решение, написанное на Java и Scala, которое используют тысячи компаний по всему миру.
Как происходит передача данных в Kafka?
Чтобы понять, как работает Kafka, представьте себе конвейер на фабрике. На одном конце конвейера работники складывают детали (это продюсеры), а на другом — их забирают для сборки (это консьюмеры). Kafka — это сам конвейер, который гарантирует, что каждая деталь дойдет до нужного места.
Вот основные компоненты процесса:
- Событие/сообщение: это единица данных, которая передается через систему. Например, это может быть лог о том, что пользователь совершил покупку на сайте.
- Key: необязательный ключ, который помогает распределять сообщения по кластеру. Например, все сообщения от одного пользователя могут иметь одинаковый ключ.
- Value: сам массив данных. Это может быть JSON, XML или просто текст.
- Timestamp: отметка времени, которая показывает, когда сообщение было создано.
- Headers: дополнительные метаданные, которые можно прикрепить к сообщению. Например, тип события или его приоритет.
Продюсер — это источник данных. Это может быть приложение, которое генерирует логи, или датчик, который собирает информацию о температуре. Консьюмер — это получатель, который обрабатывает данные. Например, это может быть аналитическая система, которая строит графики на основе поступающих данных.
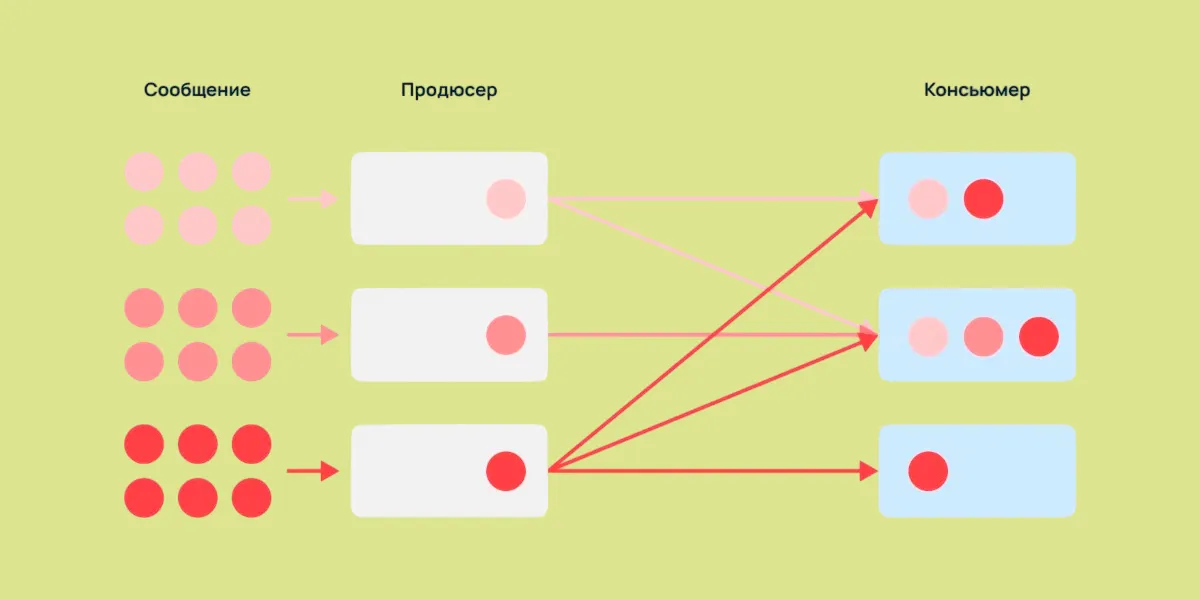
Какие проблемы решает Kafka?
Представьте, что у вас есть десятки источников данных и столько же получателей. Без брокера каждый продюсер должен знать всех консьюмеров и следить за их доступностью. Это как если бы вы сами должны были звонить каждому другу, чтобы узнать, получил ли он ваше сообщение.
Kafka решает эту проблему, предоставляя единый узел, куда продюсеры отправляют данные, а консьюмеры их забирают. Это значительно упрощает интеграцию различных систем. Кроме того, Kafka поддерживает масштабируемость: вы можете добавлять новые серверы в кластер, чтобы справляться с растущими объемами данных.
Архитектура Kafka: подробности
Kafka — это настоящий шедевр инженерной мысли. Давайте разберем ее основные компоненты:
- ZooKeeper: это координатор системы. Он отслеживает состояние всех узлов кластера и хранит метаданные. Представьте ZooKeeper как администратора, который знает, кто где находится и чем занят.
- Kafka Controller: один из брокеров, выбранный ZooKeeper, который следит за согласованностью данных.
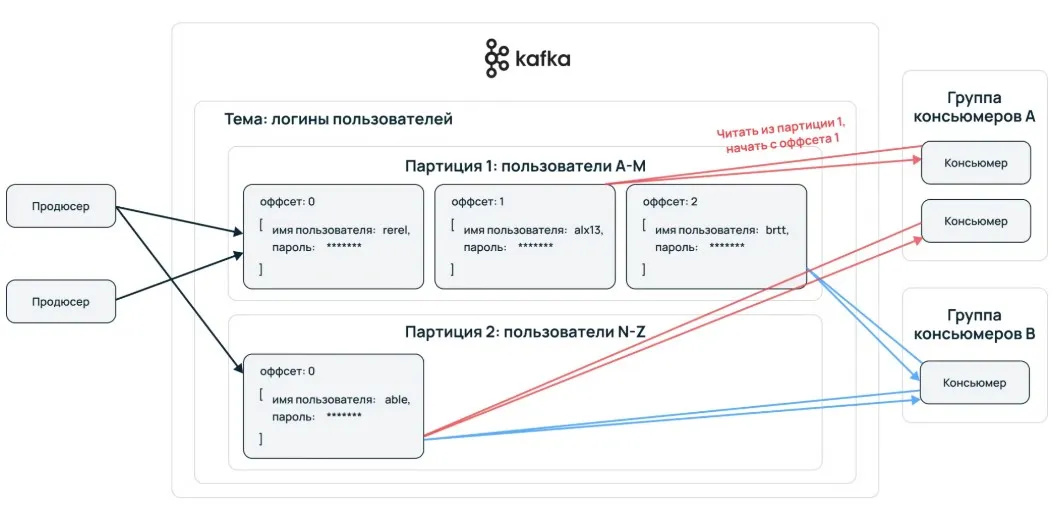
- Topic: это логическая категория, в которую помещаются сообщения. Например, все логи авторизации могут попадать в один топик, а данные о транзакциях — в другой.
- Partition: топики делятся на партиции для повышения производительности. Это как полки в шкафу: каждая полка может обрабатываться отдельно.
Одним из ключевых преимуществ Kafka является то, что она сохраняет порядок событий внутри партиций. Например, если пользователь совершает несколько действий на сайте, все они будут обработаны в той последовательности, в которой происходили.
Преимущества Apache Kafka
Почему Kafka так популярна? Вот несколько причин:
- Горизонтальное масштабирование: вы можете добавлять новые серверы в кластер, чтобы увеличить пропускную способность. Это как если бы вы могли добавлять новые полосы на дороге, чтобы справиться с растущим трафиком.
- Репликация: данные хранятся на нескольких серверах, поэтому даже если один из них выйдет из строя, информация не потеряется.
- Офсеты: если консьюмер временно отключился, он может возобновить чтение с того места, где остановился.
- API-интеграция: продюсеры и консьюмеры взаимодействуют только через API брокера, что упрощает интеграцию разных систем.
- Principle of FIFO: сообщения обрабатываются в том порядке, в котором они были получены.
Где применяется Kafka?
Kafka используется практически везде, где нужно обрабатывать большие объемы данных в реальном времени. Вот несколько примеров:
- Big Data: LinkedIn создала Kafka для обмена данными между службами. IBM использует ее для микросервисов и аналитики. Uber, Twitter, Netflix и Airbnb обрабатывают миллиарды сообщений ежедневно.
- Internet of Things: IoT-платформы используют Kafka для анализа данных с датчиков и устройств. Например, система может предсказать поломку оборудования, анализируя данные о его работе.
- Медиа: The New York Times использует Kafka для распространения контента среди различных приложений в режиме реального времени.
Конкуренты Kafka
Основным конкурентом Kafka считается RabbitMQ. Главное отличие заключается в модели доставки: Kafka сохраняет историю изменений, а RabbitMQ удаляет сообщения после доставки. Это делает Kafka более подходящей для задач, связанных с агрегацией данных и логов.

Заключение
Apache Kafka — это мощный инструмент для работы с потоковыми данными. Благодаря своей высокой пропускной способности, отказоустойчивости и масштабируемости она стала стандартом де-факто в мире больших данных. Система может быть установлена на популярные операционные системы, такие как Ubuntu, Windows и CentOS.
Если вы работаете с большими объемами данных или планируете масштабировать свой проект, Kafka — это именно то, что вам нужно. Она поможет организовать поток данных так же эффективно, как современный аэропорт управляет взлетом и посадкой сотен самолетов.